Cette question est souvent éludée dans les formations de Data Science. Elle peut être aussi légitime pour les Data Scientists n’ayant pas d’expérience ou de connaissances plus générales en développement informatique.
Imaginons que vous vous intéressiez à l’Intelligence Artificielle et que vous n’êtes pas peu fier d’avoir entraîné votre tout premier modèle. Prenons l’exemple d’une corrélation entre la vitesse d’affichage des pages d’un site web d’e-commerce et le montant moyen d’un panier (cela a été étudié de long en large : les sites d’e-commerce lents font fuir les acheteurs):
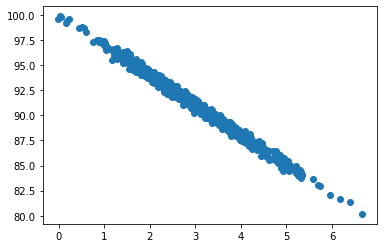
Un modèle de régression linéaire permettrait de prédire le montant moyen des achats pour un temps moyen d’affichage de 7 secondes (dans notre exemple cela tournerait autour de 70€).
import numpy as np
from sklearn.linear_model import LinearRegression
#Acquisition des données
pageSpeeds = np.random.normal(3.0, 1.0, 1000)
purchaseAmount = 100 - (pageSpeeds + np.random.normal(0, 0.1, 1000)) * 3
#Entraînement du modèle
model = LinearRegression()
model.fit(pageSpeeds.reshape(-1, 1), purchaseAmount)
#Prédiction
purchasePredict = model.predict([[7.0]])
print("Prediction={:.4f}".format(purchasePredict[0]))Décomposons maintenant le code d’un point de vue de la performance applicative. La partie la plus coûteuse concerne l’acquisition des données et l’entraînement du modèle.
| Activité | Temps | % |
| Acquisition des données | 0,0010 | 28% |
| Entrainement du modèle | 0,0024 | 65% |
| Prédiction | 0,0003 | 8% |
Comment réutiliser plusieurs fois cet utilitaire de prédiction (en ligne de commande ou par un service web) ? Les données sur lesquelles nous avons entraîné le modèle variant peu, il serait dommage de répéter à chaque appel de l’utilitaire l’acquisition des données et l’entraînement du modèle. Dans le cas d’une application métier ou d’un site Internet, cela nuirait grandement aux performances. Et à plus forte raison avec des modèles plus lourds (deep learning, modèles itératifs, etc.).
Qu’est que la sérialisation d’un objet ?
Lorsque l’on crée un objet (l’instance d’une classe comme la variable model dans notre code Python), il existe aussi longtemps que le programme dans lequel il a été créé est en vie. Dit autrement, lorsque le programme s’arrête, tous les objets créés en mémoire par ce programme disparaissent.
L’idée de la sérialisation est de rendre persistants (en les enregistrant sur le disque dur) certains objets dont on aurait besoin lorsque le programme démarre de nouveau. Dans le cas d’un service web cela concerne chaque appel au service.
Avec Python, la librairie de référence dépend du cas de figure. Joblib est à privilégier si l’on doit sérialiser de grands tableaux de nombres numpy. Tandis que pickle se montre généralement plus rapide dans les autres cas de figure.
Exemple d’un utilitaire en ligne de commande
Nous travaillerons dans le même répertoire pour tous les exemples de code qui suivent. On commencera par découper notre code en deux parties:
- Un utilitaire d’acquisition des données et d’entraînement du modèle qu’on lancera de temps en temps afin de rafraîchir le modèle.
- Un utilitaire en ligne de commande que l’on utilisera après avoir entraîné le modèle une première fois et de manière beaucoup plus fréquente.
Reprenons le code précédent afin de lui ajouter la sauvegarde du modèle dans un fichier du répertoire courant.
import joblib
import numpy as np
from sklearn.linear_model import LinearRegression
#Acquisition des données et entraînement du modèle
pageSpeeds = np.random.normal(3.0, 1.0, 1000)
purchaseAmount = 100 - (pageSpeeds + np.random.normal(0, 0.1, 1000)) * 3
model = LinearRegression()
model.fit(pageSpeeds.reshape(-1, 1), purchaseAmount)
#Sérialisation du modèle pour utilisation future
joblib.dump(model, "./model.joblib")Puis créons un deuxième utilitaire qui prendra en paramètre (par la ligne de commande) le temps de réponse et prédira le montant moyen d’achat. On l’invoque dans le terminal de cette manière: python predictor.py 7.0
import sys
import joblib
#Récupérer le temps de réponse passé en paramètre
responseTime = float(sys.argv[1])
#Charger le modèle depuis le fichier
model = joblib.load("./model.joblib")
#Prédire le montant moyen d'achat
purchasePredict = model.predict([[responseTime]])
print("Prediction={:.4f}".format(purchasePredict[0]))Utilisation dans un service web
Le principe reste le même pour un service web. On conserve l’utilitaire d’entraînement du modèle. Puis on crée avec le framework Flask (qu’il faudra installer au préalable avec pip ou conda) une application web minimaliste.
import joblib
from flask import Flask
from flask import request
app = Flask(__name__)
@app.route('/<perfRespTime>')
def index(perfRespTime):
#Charger le modèle depuis le fichier
model = joblib.load("./model.joblib")
#Prédire le montant d'achat à l'aide du modèle
purchasePredict = model.predict([[float(perfRespTime)]])
#Afficher le résultat dans le navigateur
return("Prediction={:.4f}".format(purchasePredict[0]))
app.run(host='localhost', port=5000)L’utilisation se passe en deux temps:
- On lance un serveur web depuis la console:
python webservice.pyce script écoute sur le port numéro 5000 des appels via le protocole HTTP. - Dans le navigateur on accède à l’URL http://localhost:5000/7.0 (elle contient l’adresse du serveur web et le paramètre 7.0 qui correspond au temps de réponse pour lequel on souhaite prédire le montant moyen d’achat). Notez que des applications telles que curl ou postman peuvent être utilisées à la place du navigateur.
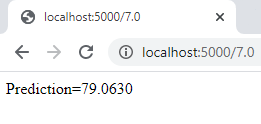
Il ne vous a sans doute pas échappé que le modèle était chargé à chaque appel du service web. En cas d’utilisation fréquente, on pourrait le mettre dans une variable statique ou globale (initialisée une fois pour toutes) ou utiliser les fonctionnalités de cache de joblib. Plusieurs choses seront alors à prendre en compte comme le nombre de services et modèles, ainsi que la quantité de mémoire disponible sur la machine.
Aller plus loin
Bien entendu, dans le cadre d’une application d’entreprise, il faudra inclure notre script dans une solution plus robuste (en incluant dans un serveur web et en y ajoutant par exemple une méthode d’authentification) et réfléchir à la mise à l’échelle. Si vous utilisez une plateforme cloud telle qu’AzureML sachez que les principes techniques et les bibliothèques python sont les même pour déployer un service web basé sur un modèle.